Configure Spinnaker on AWS for Disaster Recovery
Spinnaker disaster recovery
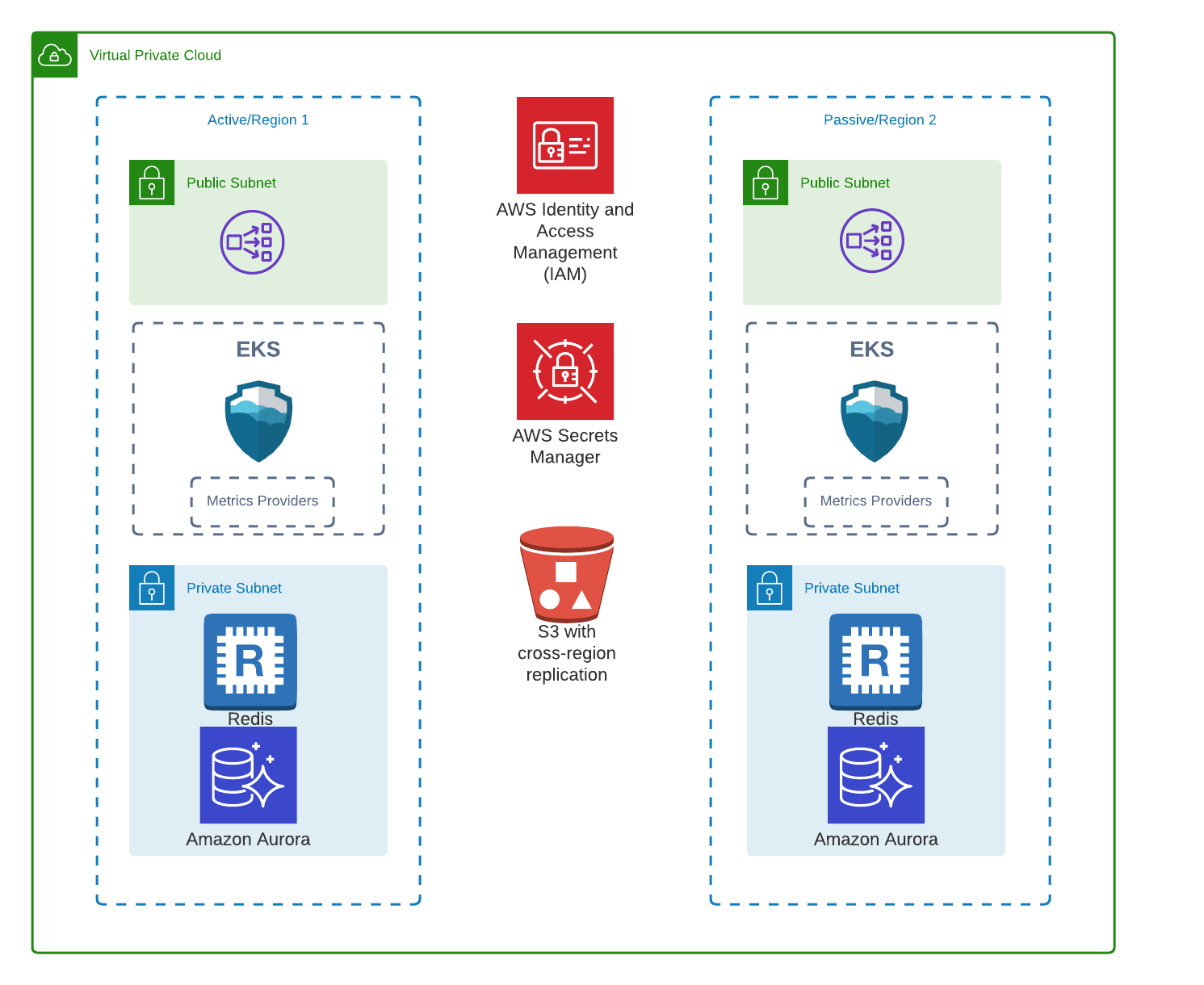
The following guide describes how to configure SpinnakerTM deployment on AWS to be more resilient and perform disaster recovery (DR). Spinnaker does not function in multi-master mode, which means that active-active is not supported at this time. Instead, this guide describes how to achieve an active-passive setup. This results in two instances of Spinnaker deployed into two regions that can fail independently.
Requirements
- The passive instance will have the same permissions as the active instance
- The active instance is configured to use AWS Aurora and S3 for persistent storage
- Your Secret engine/store has been configured for disaster recovery
- All other services integrated with Spinnaker, such as your Continuous Integration (CI) system, are configured for disaster recovery
What a passive instance is
A passive instance means that the deployment:
- Is not reachable by its known endpoints while passive (external and internal)
- Does not schedule pipelines
- Cannot have pipelines triggered by CI jobs
Storage considerations
Note
The storage you use should be replicated across regions since these contain all the application and pipeline definitions.Armory recommends using a relational database for Orca and Clouddriver. For Orca, a relational database helps maintain integrity. For Clouddriver, it reduces the time to recovery. Even though any MySQL version 5.7+ database can be used, Armory recommends using AWS Aurora MySQL for the following reasons:
- More performant than RDS MySQL
- Better high availability than RDS MySQL
- Less downtime for patching and maintenance
- Support for cross-region replication
Note the following guidelines about storage and caching:
- S3 buckets should be set up with cross-region replication turned on. See Replication in the AWS documentation.
- Consider the following if you plan to use Aurora MySQL:
- Redis - Each service should be configured to use its own Redis. With Armory services configured to use a relational database or S3 as a permanent backing store Redis is now used for caching. For disaster recovery purposes it is no longer required that Redis is recoverable. A couple things to note are:
- Gate - Users will need to login again
- Fiat - Will need to sync user permissions and warmup
- Orca - Will lose pending executions
- Rosco - Will lose bake logs
- Igor - Will lose last executed Jenkins job cursor
Kubernetes guidelines
Keep the following guidelines in mind when configuring Kubernetes.
Control plane
- The Kubernetes control plane should be configured to use multiple availability zones in order to handle availability zone failure. For EKS clusters they are available across availability zones by default.
Workers
The following guidelines are meant for EKS workers:
- The Kubernetes cluster should be able to support the Armory load. Use the same instance type and configure the same number of worker nodes as the primary.
- There needs to be at least 1 node in each availability zone the cluster is using.
- The autoscaling group has to have a proper termination policy. Use one or all of the following policies: OldestLaunchConfiguration, OldestLaunchTemplate, OldestInstance. This allows the underlying worker AMIs to be rotated more easily.
- Ideally, Armory pods for each service that do not have a replica of 1 should be spread out among the various workers. This means that pod affinity/anti-affinity should be configured. With this configuration Armory will be able to handle availability zone failures better.
DNS considerations
A good way to handle failover is to set up DNS entries as a CNAME for each Armory installation.
For example:
- Active Spinnaker accessible through
us-west.spinnaker.acme.comandapi.us-west-spinnaker.acme.comload balancers. - Passive Spinnaker accessible through
us-east.spinnaker.acme.comandapi.us-east-spinnaker.acme.comload balancers. - Add DNS entries
spinnaker.acme.comwith a CNAME pointing tous-west-spinnaker.acme.com(same forapisubdomain) and a small TTL (1 minute to 5 minute).
In this setup, point your CNAME to us-east when a disaster event happens.
Note
Armory does not recommend setting up DNS with a backup IP address when manual steps are required for failover.Setting up a passive Spinnaker
To make a passive version of Spinnaker, use the same configuration files as the current active installation for your starting point. Then, modify it to deactivate certain services before deployment.
To keep the configurations in sync, set up automation to create a passive Spinnaker configuration every time a configuration is changed for the active Spinnaker. An easy way to do this is to use Kustomize Overlays.
Configuration modifications
Make sure you set replicas for all Spinnaker services to 0. Example in SpinnakerService manifest for service gate:
apiVersion: spinnaker.armory.io/v1alpha2
kind: SpinnakerService
metadata:
name: spinnaker
spec:
spinnakerConfig:
config:
deploymentEnvironment:
customSizing: # Configure, validate, and view the component sizings for the Armory services.
gate:
replicas: 0
Once you’re done configuring for the passive Spinnaker, run kubectl -n <spinnaker namespace> apply -f <SpinnakerService manifest> to deploy.
Note
Armory recommends performing a DR exercise run to make sure the passive Armory is set up correctly. Ideally, the DR exercise should include both failing over to the DR region and failing back to the primary region.Performing disaster recovery
If the active Spinnaker is failing, the following actions need to be taken:
Activating the passive Spinnaker
Perform the following tasks when you make the passive Spinnaker into the active Spinnaker:
- Use the same version of Operator to deploy the passive Spinnaker installation that was used to deploy the active Spinnaker.
- AWS Aurora
- Promote another cluster in the global database to have read/write capability.
- Update
SpinnakerServicemanifest to point to the promoted database if the database endpoint and/or the database credentials have changed.
- Create the Redis clusters.
- Activate the passive instance.
- Set the replicas to more than 0. Ideally, this should be set to the same number of replicas that the active Armory used.
- Change the DNS CNAME if it is not already pointing to the passive Armory installation.
- If the Armory that is not working is accessible, it should be deactivated
Recovery Time Objective (RTO)
Restoration time is dependent on the time it takes to restore the database, the Spinnaker services, and the time it takes to update DNS. Most Spinnaker services that fail should recover within a 10-minute timeframe. Clouddriver may take longer especially when at scale because it needs to reconnect to all configured cloud accounts. Note that services are limited to local resources, which are configured to be redundant (databases, nodes, etc.) or highly available. In addition to Clouddriver, the following services may also take additional time to restore since Redis needs time to warm up the cache:
- Orca
- Igor
- Echo
- Fiat
Recovery Point Objective (RPO)
This is the state to which Spinnaker will recover the affected systems in case of a failure, such as database corruption. The current Spinnaker RPO target is 24 hours maximum, tied to the last snapshot of the database.
Other resources
- Kubernetes Multi-AZ deployments Using Pod Anti-Affinity
- Replicating Amazon Aurora MySQL DB Clusters Across AWS Regions
- Failover for Aurora Global Databases
- Amazon EKS
- Amazon ElastiCache for Redis
- Amazon ElastiCache for Redis - Exporting Backup to S3
- Kustomize Overlays
Feedback
Was this page helpful?
Thank you for letting us know!
Sorry to hear that. Please tell us how we can improve.
Last modified December 9, 2022: (77a2e500)